Sea-change alert…
For a while now, there has been a drive to lower power consumption in the datacenter. It began with virtualization density, continues with linux containers (fun posts coming soon on that), newer processors and their power-sipping variants, CPU frequency governors, CPU idle drivers, and new architectures like ARM and Intel’s Atom.
The sea change I’m alluding to is that with all of this churn in the hardware and kernel space, applications may have not kept up with what’s necessary to achieve top performance. My contact with customers and co-workers has surfaced a very important detail: application developers expect the hardware and kernel to “do the right thing”, and rightfully so. But customer-driven industry trends such as reduced power consumption have a side-effect: reduced performance.
Circling back to the title of this article…again, for a number of years the assumption by developers that full-bore CPU power is available 100% of the time is somewhat mis-leading. After all, when you shell out for those fancy new chips, you get what you pay for, right ? 🙂 The hardware and CPU frequency/idle drivers are biased towards power savings, I personally believe due to industry pressure, in their default configurations. If you’ve read some of my previous posts, you understand the situation, know how to turn all of that off during runtime, and get excellent performance at the price of power consumption.
But there’s got to be some sort of middle-ground…and in fact, our experiments have proven a few options for customers. For example…if you look at the C-state exit latencies on a Sandy Bridge CPU
# find /sys/devices/system/cpu/cpu0/cpuidle | grep latency | xargs cat
0
1
80
104
109
You can see that the latencies increase dramatically, the deeper you go. What if you just cut off the last few ? That turns out to be a valid compromise! You can set /dev/cpu_dma_latency=80 on this system and that will keep you out of the deepest C-states (C6 and C7), that have the highest exit latencies. Your cores will float somewhere between C3 and C0.
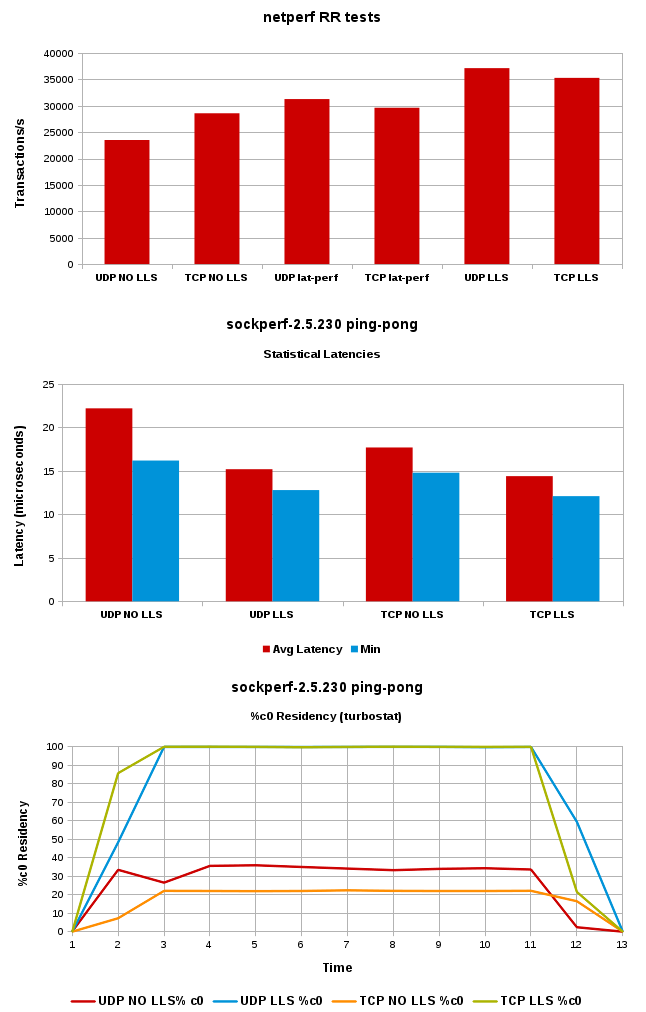
This method allows you to benefit from turbo-boost, when there is thermal headroom to do so. And we’ve seen improvements across a wide-variety of workloads that are not CPU-bound. Things like network- and disk-heavy loads that have small pauses (micro/milli) in them that allow the CPU to decide to go into deeper idle states, or slow it’s frequency. Oh by the way, the kernel recently grew tracepoints for PM/QoS subsystem. I think I could summarize this by saying if your workload is IRQ-heavy, you will probably see a benefit here because IRQs are just long enough to keep the processors out of C0. Generally I see a 30-40% C0 residency and the rest in C1 when I have a workload that is IRQ-heavy.
So when you use something like the latency-performance tuned profile that ships in RHEL, amongst other things, you lock the processors in C1 state. That has the side-effect of disabling turbo (see TDP article above), which is generally fine since all the BIOS low latency tuning guides I’ve seen tell you to disable turbo anyway (to reduce jitter). But. And there’s always a but. If you have a low thread count, and you want to capture turbo speeds, there is a new socket option, brought to you by Elizier Tamir from Intel, based on Jesse Brandeburg’s Low Latency Sockets paper from Linux Plumbers Conference 2012. It has since been renamed busy-polling, something I’m having a hard time getting used to myself…but whatever.
The busy-polling socket option is enabled either in the application code through setsockopt SO_BUSY_POLL=N, or sysctl net.core.busy_{read,poll}=N. See Documentation/sysctl/net.txt. When you enable this feature (which btw requires driver enablement…as of this writing, ixgbe, mlx4, bnx2x), the driver will busy-poll the hardware RX queue on the NIC and thus reduce latency. As mentioned in the commit logs for the patch set and the kernel docs, it has the side-effect of increased power consumption.
Starting off, I talked about looking for balance between hardware/idle driver power-savings BIAS, and performance (while retaining as much power savings as we can). The busy-polling feature allows you to (indirectly) lock only those cores active for your application into more performant C-states and operating frequencies. When your socket starts receiving data, the core executing the application owning the socket goes almost immediately to 100% in C0, while all the other cores remain in c6. As I said, without the socket option, only 30-40% of the time is spent in C0. It’s important to note that when the socket is NOT receiving data, the core transitions into a deep c-state. This is an excellent balance of power and performance when you need it.
This allows the cores being used by the application to benefit from turbo speeds, which explains why busy-polling outperforms the low-latency tuned profile (which effectively disables turbo by locking all cores into C0). Not only does this option outperform the c-state lock (because of turbo boost), it also helps achieve a more favorable balance of low latency performance vs power consumption by allowing other cores in the system to go into deep c-states. Nirvana ???
Back to macro: the busy-polling knob is only one way that developers should ask for the CPU these days. The second (and as I’m told under authority), preferred way to instruct the CPU what your application performance tolerances are, is through the /dev/cpu_dma_latency interface. I’ve covered the latter in a previous article, please have a look.
And here’s what I mean:

One thought on “Oh, did you expect the CPU ?”