I tried hard to make it work. But I could never get the results I wanted. The crisp video, clean audio, the BOKEH. Herein lies my adventures (full send, some might say) over the past ~2 months in getting a proper home office A/V setup. It’s not perfect yet, but I’m fairly happy with the improvement. I’ll close this write-up with some of my next steps / gaps.
Starting with some basic tenets:
- Whatever I end up with has to augment all of my ingrained behaviors; I’m not going to relearn how to use a computer (change operating system) for the sake of this.
- I’m stuck with the room I’ve got. The walls have odd angles which makes lighting difficult.
- I don’t know anything about this, so there will be lots of trial, error, and Googling.
I started by scouring YouTube for videos about the ultimate camera setup for WFH. It turns out the center of knowledge in this area is Twitch streamers. There are also a few companies posting setups who are more business focused, feels like they’re using these videos to promote their consulting businesses (which are around video editing, or promoting small business). Twitch streamers also know a lot about Open Broadcaster Software, but I’ll get to that in a bit.
Camera
After seeing this blog come across my Twitter, I impulse-buy a GoPro Hero 8 Black. Turns out GoPro is completely ignoring Linux and their webcam firmware is really, really beta even on Mac and Windows. Returned it.
After watching a lot more of these videos, I started seeing a trend towards a particular Mirrorless DSLR camera, the Canon EOS M50. I’m trying to stay with models that folks recommend for WFH/streaming, and that I can find SOMETHING saying they support Linux / have anecdotal evidence of it working. So I bought a Canon M50. I had to buy it from a place I hadn’t shopped at before (Best Buy), because a lot of people are trying to up their WFH A/V game, making components scarce.
So I’ve got the camera. I also need a micro HDMI –> USB 3 cable, so I got one of those. Elsewhere in the YouTube blackhole, I came across the term “dummy battery”. This is a hollow battery that lets you plug the camera directly into wall power to avoid having to use real batteries and their runtime limitations. Canon dummy batteries were sold out everywhere, including Canon themselves, although I did place an order with them directly (their web purchasing experience is stuck in early 2000s). It was on backorder, so I eventually canceled that order and bought a knockoff dummy battery for 20% of the price of the real one. Was I worried that something 20% cheaper would instantly fry my camera? Yep. But I am in full send mode now.
So I have the camera, the HDMI cable, the dummy battery. I probably need a tripod, right? I think cameras need tripods. OK, I got a tripod. Not sure what I’ll use it for, but I can always return it. Turns out the tripod was a key investment in making sure the camera is stable, level and oriented properly for the right angle.
Next I probably need a memory card, right? Cameras need memory cards? OK, I’ll get a memory card. But which one? I’m planning to put down 4k video @ 60 fps so “sorting by least expensive” is probably not the right move. Turns out there is a whole disaster of categorization of memory card performance. I ended up reading, and re-reading this page a few times. What a nightmare. The least consumer-friendly thing since 802.11 spec naming. Anyway I ended up buying a 128GB class 10 card and it seems to be fine.
I then have to connect the camera to my computer. The videos suggest HDMI, but Canon has recently announced USB support for live-streaming. This blog in particular was referenced in a few videos. Lets try that. OK, now I am into the land of having to configure and load out of tree kernel modules. How do you do this again? It’s been a while. OK, got it. Whew. How badly do I want the BOKEH? This is getting dicey and doesn’t feel right.
Well, it actually works. But it is FAR from ideal. The fact that I’ve got to run gphoto2 on boot, and install all this goop to wire things together … there has to be a better way?
I began using this setup for the first time in real video calls (we use Google Meet where I work). The quality was infinitely improved (making sure my Meet config used 720p and after literally days of experimentation with camera settings). People immediately noticed the difference too. However, sometimes the camera would shut off? I noticed a trend of it shutting off after about a half hour? But I have the dummy battery. What’s going on?
I will spare you the suspense. If I’d found this page, I’d never have bought the Canon M50. It shuts off after a half hour on purpose. There’s no way around it. Also the Canon M50 is not compatible with Magic Lantern firmware. What is Magic Lantern? Something I don’t want to deal with. Gone are my days of CyanogenMod on my Palm Pre (by the way, the Palm Pre was better than any phone I’ve owned before or since, don’t @ me).
So, my Canon shuts off. That’s just about the worst flaw it could have. Back to Best Buy. But not before the 14 day return policy expires, so I can’t do it online, I now have to physically visit a Best Buy to haggle, or eBay it. Despite COVID situation, I decided to mask it and haggle. Luckily they took the camera back, yay. If you’re interested in why it turns off, I found this post which is probably right…yeesh!

Next, what camera should I go for? Elgato’s page made it super easy to find cameras of a similar price-point that didn’t have any glaring flaws.
After much more fact-checking, I decided to get a Sony A6100. This time Amazon had it in stock, and significantly cheaper than other sites (price gouging?). The Sony arrives and it is immediately more useful (because it doesn’t shut off). Incidentally, I had to buy a different dummy battery for the Sony. An off-brand, that has thus far not fried my camera. Tripod, memory card and HDMI cable were compatible.
Next, how to connect this to my computer. The Sony also supports USB, but I’m not happy with the quality. It also uses a lot of CPU. What solutions are there? After many a sleepless night on YouTube learning what a “capture card” is, I went to find the highest end model, and found an Elgato 4K60 PRO PCI capture card. Wow, this was a total waste of time. Not only does it have zero Linux support but it feels like Elgato is actively ignoring Linux across the board, which is possibly corroborated by my experience with their CamLink 4K as well(?). I end up searching my email for that phrase in case some other intrepid Red Hatter is further along than me.
It turns out that an engineer whom I hired ~4 years ago, and who I allegedly sit next to in the office (it’s been 6+ months, and I’m full sending my home office, maybe I’ll never see him again), wrote a post about capture cards in May 2020! I have learned to trust this person’s opinion on these sorts of niche devices, because he has described his enviable Plex setup (it has a dedicated air conditioner), his GPU bitcoin mining, Threadripper prowess, and other things to me over lunch which indicate he has a nack for understanding things at the level of detail that I need for my BOKEH. His post pointed to a Magewell USB Capture HDMI 4K Plus Device. In particular he had tested it on Fedora and noted how hands-off it was for setup. His complaint was noise about a built-in fan. After balking at the price, I decide that it can be returned, so I get one. It turns out he was right, and it works great! One thing though is that I haven’t heard the fan at all, which I guess is good. Thanks to Sebastian for this tip.
However its really expensive. And the YouTubers are telling me about Elgato CamLink 4k which is 1/3rd the price. I get a CamLink 4K and decide that if it works, I’ll return the Magewell to save the money. Hook up the CamLink, the kernel sees it as a uvc device, but I see nothing but a black screen in OBS and Google Meet. After an hours worth of effort and Google turning up several complaints on this topic (admittedly not a huge effort on my part), I decide to trade money for my weekends/evenings back, and stick with the Magewell. Sebastian was right again. Hat-tip.
Audio
On to Audio. Last year I hired an engineer who turned out to be in two metal bands. On video calls with him, he had what looked like a very serious A/V setup in his home office. If you’re into Dual-Violin US Folk Metal, maybe check them out. Anyway, this person gave me some guidance on audio and I ended up going with a Blue Yeti USB Mic. This is one aspect of this journey that worked on the first try. However I could not help but think maybe there’s a way to improve? At conferences, when they were in-person, presenters get a lavalier mic. I bought one and it wasn’t any better. Also it was annoying to have a cable dangling from my collar all day. Returned.
For years I’ve been using Bose active noise cancelling headphones (at the office which is an open-office disaster / cacophony). At home I also bought Bose ones, but the in-ear model. The only thing I don’t like is that they’re wired, so I’m tied to the desk. One thing I do like is that they’re wired, so I never have to worry about batteries like I do with the ones I have at the office. I also have a pair of noise cancelling Galaxy Buds (which I love). I decide to try those. Ahh, my workstation doesn’t have Bluetooth. Back to Amazon to get a cheap bluetooth dongle. And now the Galaxy Buds work. But the experience sucks, for a few reasons:
- I have to worry about batteries
- They disconnect if I walk down the hall
- Pairing is less than ideal in Linux where I have ~5 audio devices
- I notice a lot of CPU usage tied back to the Bluetooth device…not good.
- I decide not to die on this hill, and stick with the Bose QuietComfort 20.
I have the Video and Audio basically squared away at this point. What’s next? Lighting.
Lighting
The majority if howto videos indicate that if you don’t have proper lightning, it won’t matter your camera or software. I begin to research lighting, and found that Elgato Key Lights are a popular thing. You apparantly need two of them, they’re $200 each, and they’re out of stock. So, nope. I have a spare floor lamp and decide to use that. This is much better than the ceiling fan light I had which was casting a very scary shadow on my face 🙂 So the lamp is to my east-south-east, pointed towards the ceiling and I’m OK with the results. This is an area I may eventually want to improve, but maybe I’m nearing diminishing returns time-wise?
Software
Conferences have gone virtual, and I have several presentations lined up, which are all typically recorded. So now I need to figure out how to record myself. According to YouTubers, I need to figure out what OBS stands for. The Open Broadcaster Software is (apparently) an open source streaming/recording application available for Windows, Mac and Linux. I am now watching EposVox masterclass on OBS. It’s complicated but not terrible to do basic stuff. You can see my first stab at integrating my efforts into a recorded presentation here.
After watching that video back, I have a few areas to improve:
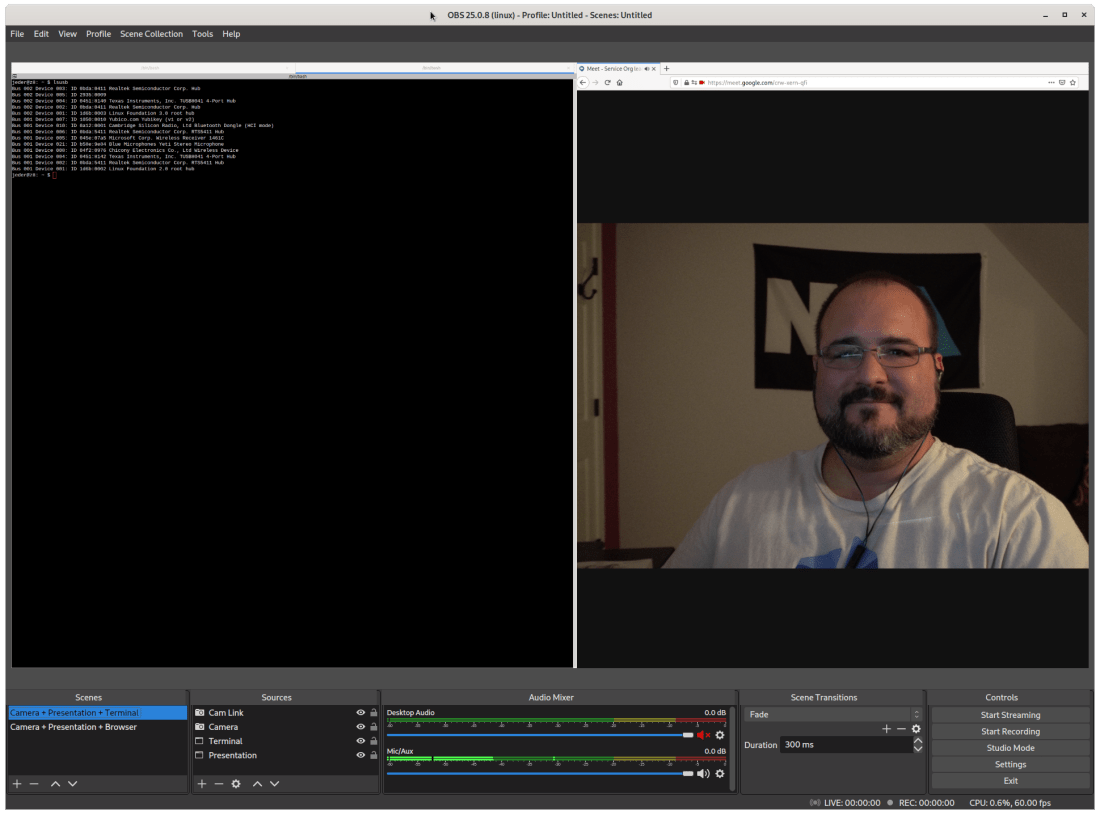
- I keep having to pause the recording to load the next section of content into my brain. I have to keep looking down to pause. There are apparently things called Elgato Stream Decks, which are a pad of hotkeys which are used by game streamers to automate certain operating system or OBS operations. OBS also supports hotkeys. Here is what my OBS canvas looks like including a few video sources and scenes:

- I am not looking into the camera often enough. Yes, I have to look at my monitor to do demos and whatnot (expected), but I am also looking at my monitor to check my notes. I want to avoid that somehow. It turns out that Phone-based Teleprompters are a thing, and in-expensive. I bought one. It’s freaking cool. Mounts directly to the camera lens and displays the “script” overlaying the lens itself. So you are staring directly at the lens, and have a “Star Wars intro” style scrolling text of your content. Cannot recommend this product enough for professional delivery of recorded content. It even comes with a Bluetooth remote to control scrolling speed and start/stop. That dongle comes in handy again!
- I want to involve whiteboards in my presentations. In the office, I have whiteboards available to me everywhere. I need one at home. But due to the size and shape of my office, I really don’t have a wall within camera-range to mount one. So I went with one on wheels. I haven’t used it in any presentations yet, but I’ve been using it for keeping notes and so far loving it.
- I have to learn how to do basic video editing. After some Googling for the state of the art on Linux, I found Kdenlive which isn’t terrible to learn, after watching a few beginners videos.
- I realize the audio is out of sync with the video. OBS let me insert a delay to help match then up. 300ms seems to be perfect.
- In the original version of this video, the audio was super low. So I had to learn how to convert an mkv (OBS default) to an mp4, so I can work with the audio independently of the video, and boost the audio gain (by +20dB if you’re curious). Thanks to some quick tips from Langdon White I am able to achieve this. At this point my various experiments and YouTube deep dives are starting to pay off. I am smiling, finally 🙂
Next Steps
- For some reason, when I turn off the camera, the zoom level resets to 16mm. But I want it at 18mm. So every time I turn the camera power on, I have to dial the zoom back in manually. Not a huge deal since it’s just once a day.
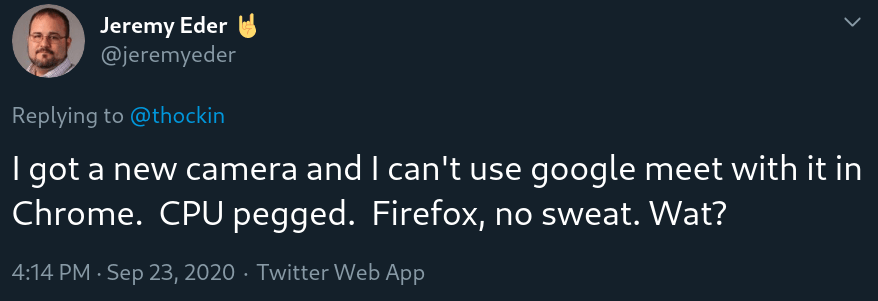
- CPU usage in Chrome…brings the computer to a crawl. My workstation has 16 cores and 64G RAM. Sigh…so now all my Google Meets occur in Firefox. Not too bad, just annoying when it comes to screensharing since I really do not want to use Firefox as my primary browser.
- Lens: according to photography snobs, if I don’t get a better lens, they’ll throw me out of the subreddit. This will probably have to wait until after my winning lotto ticket shows up.
- After talking with some coworkers who are also upleveling their WFH A/V setups and thus learning what OBS stands for, I come to find out that OBS has some noise filtering options built in. I could have used that to filter out some background noise (e.g. from my kids or my workstation fans).
Conclusion / Final Hardware list
So, in the end, my hardware and software setup as of this posting is:
- Sony A6100 Camera, Dummy battery and HDMI cable
- Tripod
- Magewell USB Capture HDMI 4K Plus capture card
- Parrot Padcaster v2 Teleprompter
- Mobile Whiteboard and markers
- MicroSD to SD memory card adapter and USB SD card reader
- Latest versions of Kdenlive, Audacity and OBS
I have to say, this has been a really fun project. It’s an area I had zero knowledge of going in – just a personal goal to improve my WFH A/V. It’s also an area of somewhat daunting complexity, hardware opinions (nerd fights), and an endless compatibility matrix. That’s part of why I went the route of buying stuff and returning it [1].
I hope this post helps someone who is looking to improve their home office video quality avoid newb mistakes and just get it done. Also, I do realize that there are likely cheaper options across the board. But at least you have the laundry list of stuff that worked for me, within my given constraints, and can possibly phase your purchases like I did over a couple months.
[1] always check the return policy 🙂
List of Useful YouTube Channels




 storage device used for docker’s graph storage.
storage device used for docker’s graph storage.