Earlier in August 2023 I changed roles within Red Hat. My new role is “Chief AI/ML Platform Strategist”, and organizationally is part of Red Hat’s OpenShift AI product group.
I’d been in my previous role for ~5 years, and celebrated my 14th anniversary at Red Hat last month 🫶 . My previous team (Red Hat Service Delivery) afforded me endless technical challenges, opportunities to launch new services, present, help define technical strategy and build cross-org engineering teams to support that strategy, from the ground up. Equally important to me was the opportunity to mentor as many Red Hatters as I possibly could.
And now, on to the next chapter. Red Hat’s CEO Matt Hicks did an interview recently that describes how Red Hat will participate in the AI/ML ecosystem as a platform company, specializing in machine learning operations (MLOps). My role involves working with engineering and product leaders to devise a strategy that will deliver a sustainable open source, enterprise software business around artificial intelligence and machine learning.
If I could summarize this north star in one sentence, it would be answering this:
I trust Red Hat as a strategic partner in the AI/ML space because…
Prospective Customer (Exec, Engineering personas)
The OpenShift AI product group encompasses:
Development teams that design, build and operate Red Hat OpenShift Data Science (both as a SaaS and on-premise).
Product / business teams that provide the vision, mission and roadmap (for an extremely fast-moving space!).
Community participation in opendatahub.io and other upstreams
By bridging development, product, upstream communities, partners and consortia, we aim to increase Red Hat’s participation and brand association in strategic AI/ML areas through deliberate and substantial technical and business contributions to the ecosystem.
In many ways this is akin to work I and others did for the OpenShift product group in the 2013-2018 timeframe, when a similarly fast-moving space was in its gold-rush phase. Red Hat needed a voice in strategic upstreams (mainly Docker, Kubernetes, Linux Kernel) so that we could build a successful, sustainable product that covered workloads our customers cared about.
I’d personally gotten involved from the performance/scalability standpoint as an SME for running performance-sensitive applications on OpenShift (including GPUs). A lot of foundational work needed to be done — and Red Hat’s philosophy is to participate in, and catalyze open source communities to complete foundational work that allows the ecosystem to thrive, and deliver on participant business goals.
As I sit here, it all feels very “full-circle” for me, as I come back to a space I’m wildly passionate about, and that as an infrastructure platform company, Red Hat is uniquely positioned to provide differentiated value for.
In summary — in the few weeks I’ve been (re)digging into this AI/ML Cambrian explosion, it looks just like the early 2010’s. Most importantly, I am convinced that there is enough “real” here to justify the current hype. We are headed for industry consolidation. There are daily land-grabs going on in terms of marketing / positioning. And, as with many new technologies, there are important ethical, legal and governance questions yet un-answered (especially wrt LLMs, GDPR and compliance). Over time this space will settle down a bit, and one of my primary goals is to position Red Hat appropriately, as that occurs.
Hopefully $subject makes a bit more sense now. Onward!
P.S this blog contains 0% AI-generated content. All grammar errors are mine 💪
It’s both exciting and nerve-wracking to develop highly visible production service platforms. Exciting, in that the ideation phase of creating a differentiated offering inspires “creatives” in the software engineering space to do their best work. Nerve-wracking, in that knowing the details of implementation, and what hit the editing room floor during planning/prioritization exercises, carries with it a certain sense of responsibility — especially if you end up being caught-out on any of those areas as “real usage” begins.
There was a fantastic paper written last year on the topic of creativity in software engineering. Highly encouraged reading, especially for software engineering managers, technical team leads, those involved in hiring/promotions and so forth.
In order to solve today’s complex problems in the world of software development, technical knowledge is no longer enough. Previous studies investigating and identifying nontechnical skills of software engineers show that creative skills also play an important role in tackling difficult problems.
For this blog, I’ll focus on the experience the team I led went through during the bring-up of a highly visible service launch scheduled for March, 2021 called Red Hat OpenShift on AWS (ROSA).
The ROSA service was a first-of-its-kind, first-party offering (transacted through Amazon) that would be added to the AWS console. That set the high bar for the team to deliver on what the business partnership between Red Hat and AWS had negotiated. Shortly thereafter additional first party services from partners were added to AWS console (Grafana has one at least). But indeed ROSA was the first 🙂
That led us within engineering to struggle a bit with not only quantifying readiness, but also a gut-check on whether we’d launch with a sufficiently differentiated offering that was compelling enough to drive sales and delight customers. Lessons from lean management, lean startup and so forth are salient here, and were appreciated and emphasized by both management and technical leaders who are responsible for our engineering culture.
I estimate that if you did a straw poll at the time about our readiness, the room would have been split 50/50 on a go/no-go. My impression on that split was that we all as humans have different “risk defaults” that play out more generally in our life (think about modulating risk in one’s investment portfolio). The leadership team’s feedback was “If you’re totally comfortable to launch, you’ve waited too long.” And that’s totally right. While we have very high standards not only for ourselves as engineers and SRE, but also for Red Hat as a whole in terms of reputational risk, getting out there into the market, and building the the habit of “going to the Genba” is the correct and primary path to success.
I think it’s most folks (engineers especially) default approach, when being introduced to a new system, product or idea, to immediately want to understand “how” something works. This blog is to specifically challenge that default, turn it around, and pose that we default to “why” something works. Why it has to exist, and why it is the way it is.
People are “how-constrained”. I have this thing, I know how it works. And then little tweaks to that will generate “something”. As opposed to: what do I actually want, and then figure out how to build it. It’s a very different mindset. And almost nobody has it, obviously.
Jim Keller & Elon Musk
The flaw, maybe fatal even, about being “how-constrained” is that you have a tendency to ignore, or not fully appreciate, the bigger picture found in “why”. Let’s take for example building a product at your company.
By the time requirements hit engineering, most of the “why” has been discovered, measured, discussed, justified and “talked out”. I argue that if product and management teams do not clearly articulate, strategically and in “addressable-market” terms, the “why” to engineers, you miss an important cultural motivating factor in building healthy teams. You also miss an opportunity to have some of the brightest minds check your work. Never skip the step of clearly articulating “why” we’re embarking on building a new thing, and how decisions were taken.
That is not to say that the position of “naturally worrying about how” is not a critical behavior and attribute. It is that we must continually question our “why”. There must be a feedback loop, and one of the expected outcomes of that is that status quo’s are continually challenged.
Lastly, I’ve noticed that being “how-constrained” inherently limits vision in even the most talented groups. I’ve also noticed a soft correlation between seniority and being less how-constrained, although that seems to be valid only at the most senior levels. If you see yourself over-rotated towards “how”, try for a moment being “why-constrained” and see how it frees your thinking + gets your creative juices flowing. I know that it does for me.
“We often think of movements as starting with a call to action. But movement research suggests that they actually start with emotion — a diffuse dissatisfaction with the status quo and a broad sense that the current institutions and power structures of the society will not address the problem. This brewing discontent turns into a movement when a voice arises that provides a positive vision and a path forward that’s within the power of the crowd.” — Harvard Business Review
The idea behind SIG-SRE started just like that — with emotion, and knowledge that the status quo would not produce the outcomes that Red Hat needs, in the timeframe it needs them, to become competitive in the managed services business.
In addition to the fun video we created for the kickoff, the team has put together a coloring book to highlight how SREs think and how the practice of SRE impacts service using a Kitchen Nightmares restaurant analogy.
The coloring book talks about five principal aspects of SRE and provide a self-assessment scorecard for readers to evaluate themselves:
Observability
Safety and self-healing
Scalability
Shifting left
Zero downtime
Like other Red Hat coloring books, we’ll use it at trade shows in it’s printed form, marketing will do their thing, and as an internal tool for facilitating conversations around building operable software.
Have a look at let us know what you think. Feel free to use it at your company!
During my career at Red Hat, I’ve had the great pleasure of being a go-to person to bootstrap $things. After a good amount of repetitions, I’ve arrived at a bit of a blueprint on how to do it. Each go at it becoming more and more refined and incorporating lessons learned as each $thing presents its own nuances.
As an engineer exploring ways to bootstrap $things, Simon Sinek’s book Start with Why deeply resonated with me. I began looking for frameworks that let me capture “why” in a way that has unyielding precision, and found the Patrick Lencioni’s Six Critical Questions section in his book The Advantage.
I’ve now used this format several times and am continually impressed by how durable it is. If you can capture the essence of the new $thing in this format, you can look back on it even years in the future, and your intent remains unambiguous.
Further, and most importantly, executive stakeholders and beyond can see exactly what’s being bootstrapped, the why and how. This leaves no ambiguity — all that remains is execution and follow-through.
From Patrick Lencioni: “Creating alignment at the executive level is essential to building and maintaining a healthy organization. There is probably no greater frustration for employees than having to navigate the politics and confusion caused by leaders who are misaligned. Even the slightest bit of daylight between executive team members can cause an overwhelming effect on employees below. There are six simple but critical questions that need to be answered, eliminating all discrepancies among team members.”
This approach reduces the risk of that daylight ever seeing the light of day.
Most recently I bootstrapped the internal special interest group for Site Reliability Engineering called SIG-SRE. I even made a fun video for the kickoff 🙂
The SIG-SRE project is an effort to seize horizontal opportunities created by Red Hat offering managed services. SIG-SRE will support efforts like Operate First, internal communities of practice, and Red Hat University.
Q2: How do we behave?
We develop consensus amongst accountable parties and output process and procedure to be implemented amongst teams. We will extract strategic value from in-practice SRE teams and bring reusable value back to ourselves.
Q3: What do we do?
We will lead in building the practice of SRE across the company. We will bear down on the core shared problems that enable Red Hat to build a competitive managed services business.
Q4: How will we succeed?
We will take an upstream first (Operate First) approach to ensure Red Hat’s core ethos is carried forward into the managed services space. You can see this commitment delivered here.
The vast majority of participants will participate in on-call rotations for their existing service teams.
We will be accountable for goals that the SIG participants set, guided by the needs of groups and the company at large.
Ensure new processes include clear roles and responsibilities (RACI)
Ensure the SIG is deeply tied into training efforts to enable existing associates to succeed (e.g. PMs, traditional developers)
Q5: What is most important, right now?
Build consensus about the opportunity and approach.
That the SIG becomes a force multiplier, allowing engineering teams to benefit from economies of scale, lifting all our boats.
Q6: Who must do what?
If this problem space resonates with you, discuss with your management chain and tech leads how your team can best support SIG-SRE by allocating specific engineering and BU/PM resources. We will not achieve escape velocity with favors and part timers. The value to a team in allocating engineering time to the SIG should come back to them, in multiples, in a measurable way, in a finite time frame.
The title of this blog is a quote from James Clear’s Atomic Habits book. The tl;dr of this book is a set of strategies to get 1% “better” each day.
If that’s the case (and I certainly agree), here are some of the recent votes I cast and why.
Completed a higher ed management curriculum in strategy and innovation. I cast this vote so that I could learn new models for expressing existing or new ideas in a way that more effectively conveys the substance to stakeholders. I also met a ton of wildly successful business leaders and faculty that I otherwise would not have had access to.
Worked with our engineering and management teams to re-plan a major project so that we can incorporate additional engineering resources and adjust to more aggressive timelines. I cast this vote because our existing plan would not meet business objectives and that’s not my style.
Proposed structural changes for Red Hat engineering as a whole to set ourselves up for a more sustainable future (firm believer that structure dictates behavior). I cast this vote because our strategic goals were drifting out of alignment with incentives and goals for the IC levels.
Met with Emerging Tech group to identify ways for them to support our managed services growth and technical strategy. I cast this vote because while our CTO office incubates fantastic new and innovative technologies, we have to leverage those skills in different ways in the future.
Worked with an internal team on strategy documents to draft a position paper on “Open Services”. I cast this vote because I believe firmly in Red Hat’s business model and want to see its core ethos carried forward into the managed services world.
Kept up my mentoring schedule. I cast this vote because I want to remember how my mentors affected me and pay it forward. Oliver Parker, here’s to you sir.
Worked with a small group of folks to create a coloring book on Site Reliability Engineering called Reliability Nightmares. Red Hat has over the years delivered a number of coloring books for topics we care about. I cast this vote because “culture eats strategy for breakfast” and I felt this would be a fun tool in fostering a movement.
I’m still digesting the rest of this book, but wanted to get some basic thoughts about this particular quote written down.
I wrote this post in July 2017, and I just found it (4 years later) in my Drafts folder. What a great journey down memory lane it was to read this today. Ask 2017 me if he knew what he’d be into 4 years on, and…yeah. Life moves pretty fast.
We have been doing a lot of hiring lately — I am lucky to be at such a company. It feels like that’s all we’ve done over the time that I’ve been at Red Hat. In every interview I am routinely asked what is it like to work at Red Hat. Mostly I’d pass on a few relevant anecdotes, and move on.
As I’ve just come up on my 8 year anniversary at Red Hat, I thought I would write some of this stuff down to explain more broadly what it’s like to work at Red Hat, more specifically in the few groups I’ve been in, more specifically my personal experience in those groups…
How did I get here?
In 2007, I met Erich Morisse at a RHCA training class at Red Hat’s Manhattan office. Erich was already a Red Hatter, and somehow I ended up with his business card. Fast forward a year or so, and…
I got married in 2008 in Long Island, NY. Within 3 months of that, I applied at Red Hat and flew to Raleigh for the interview. Within 4 months of that, my wife and I moved to Raleigh, and I started at Red Hat on July 20, 2009, as a Technical Account Manager in Global Support Services. I was so excited that they’d have me that the 15% pay cut didn’t bother me.
Life as a TAM
I think there are still TAMs in Red Hat, but I won’t pretend to know what their life is like these days. My experience was filled with learning, lots of pressure and lots of laughs. We had a great group of TAMs…I am still in contact with a few, even 6+ years later. As a TAM we are ultimately tasked with keeping Red Hat’s largest accounts happy with Red Hat (whatever the customer’s definition of happy is). That can mean a variety of things. I personally found that the best way to build and maintain a good relationship was to be onsite with the customer’s technical team as much as possible. While that meant a lot of 6:00am flights, I think it ended up being worth it if only to build up the political capital necessary to survive some of the tickets I’ll describe below.
At the time, TAMs carried about 4-6 accounts, and those accounts largely came from the same vertical, whether it was government, military, national labs, animation studios, and my personal favorite FSI (financial services industry). I gravitated towards the FSI TAMs for a few reasons:
They were the most technical
They had the most pressure
I felt I’d learn from them
I ended up moving to that sub-group and taking on some of the higher profile banks, stock exchanges and hedge funds as my accounts. Supporting those accounts was very challenging for me. I was definitely in over my head, but actually that is where I thrive. For whatever reason, I naturally gravitate towards pressurized, stressful situations. I think there was an experience at a previous job at a datacenter operator (where we were constantly under pressure) that made me learn how to focus under duress and and eventually crave pressure.
I’ll relay two stories from my time as a TAM that I will never forget.
2010: Onsite for a major securities exchange platform launch (moved from Solaris to RHEL). This led to one of the nastiest multi-vendor trouble tickets I was ever on. That ticket also introduced me to Doug Ledford (now one of the Infiniband stack maintainers) and Steven Rostedt (realtime kernel maintainer, sadly now over at VMware). In retrospect I cam see how much I grew during the lifetime of that ticket. I was getting access to some of the best folks in the world (who were also stumped). Helping debug along with them was truly an honor. I think we went through over 40 test kernels to ultimately fix it.
2011: A customer purchases a fleet of server gear that has buggy NICs in every aspect. Firmware is terrible. Drivers are not stable or performant. While the hardware issues were not on my plate, certainly the drivers in the kernel that Red Hat was shipping were very much my responsibility. In this situation, I made several trips out to the customer to ensure them that everything was being done to remedy the situation. I knew this was a serious issue when each time out there I was presenting to higher and higher ranking management. We worked with that vendor daily for quite a while. They fixed bugs in both firmware and driver (upstream), Red Hat kernel folks backported those patches and we tested everything onsite. I don’t know if we got to 40 kernels, but it was at least 20. Plus a dozen or so firmware flashes across roomfuls of machines. This scenario taught me:
I needed to up level my public speaking experience if I was going to be in rooms with highest levels of management. To do this I joined local Toastmasters club along with another TAM. That other TAM founded Red Hat’s own chapter of Toastmasters, and I was the first to speak at it.
I should get more hands on experience with high end hardware itself so that I could relate more to the customer’s Ops folks. I ended up working with some gear loaned to me by Red Hat Performance team. They always seemed to have the cool toys.
More about tc, qdiscs, network buffers, congestion algorithms and systemtap than I’d care to admit.
At time time, I felt like I barely survived. But feedback I received was that I did manage to make the best of bad situations, and the customers are still customers so…mission accomplished. I also became the team lead of the FSI TAMs, and began concentrating on cloning myself by writing documentation, building an onboarding curriculum and interviewing probably 3 people a week for a year.
Becoming a performance engineer
After working with those exchanges, I knew a thing or two about what their requirements were. I got a kick out of system tuning, and wanted to take that to the next level. My opportunity came in a very strange way. Honestly, this is how it happened…I subscribed to as many internal technical mailing lists as I could. Some were wide open and I began monitoring them closely to learn (I still do this).
One day a slide deck was sent out detailing FY12 plans for the performance team. I noted buried towards the end of the deck that they planned on hiring. So, I reached out to the director over there and we had about an hour long conversation as I paced nervously in my laundry room (it’s the only place I could hide from my screaming infants). At the time, that team was based in Westford, MA. I flew up there and did a round of interviews. Within a few days, I was hired and planning my transition out of the support organization.
I believe what got me the job was that I had learned so much low level tracing, and debugging hackery while supporting the FSI sector that I ended up doing very similar work to what was being done on the performance team. And that experience must have shone through.
Being a performance engineer
I remember my first project as a performance engineer: help the KVM team to see if they could use ebtables to build anti-spoofing rules into our hypervisor product called Red Hat Enteprise Virtualization. I remember thinking to myself…oh shit…what is RHEV? What is ebtables? I was under pressure again. Good. Something familiar, at least. To help out the RHEV team I had to quickly learn all of the guts of both topics as well as build load/scale tests to prove out whether it would work or not. I’ll skip to the punchline though…ebtables is abandonware, even 6 years ago. No one cares to fix anything and it’s been on the guillotine for a long time. Based on the issues encountered, I might have been the first (only?) person to really performance and scale test it.
This initial experience was not unlike most experiences on the performance team:
You generally have no clue what the next project will require, so you get very good at soaking up new material.
Don’t be surprised…you are likely the first person to performance or scale test a feature. Get used to it. Developers develop on their laptops.
Most of that is still true to this day — although as time went on, I learned to be more proactive and to engage not only with developers about what they’re working on, but also religiously reading LWN, attending conferences like LinuxCon and like I mentioned, subscribing to as many mailing lists as possible.
The biggest project (not for long) I had on this team was the initial bringup of RHEL7. I look back with great fondness on the years 2012-2014 as I was able to see the construction of the world’s leading Linux distribution from a very unique vantage point: working with the very people who “make RHEL feel like RHEL”. That is … debating over kernel configs…backwards compatibility discussions…working with partners to align hardware roadmaps…GA/launch benchmark releases…can we do something like kSplice…will we reduce CONFIG_HZ.
This last bit brings me to the part of RHEL7 that I had the most to do with…timers. As the vast majority of financial transactions happening on stock exchanges occur on RHEL, we had to pay very close attention to the lowest levels of performance. Timers are an area only the smartest, bravest kernel developers fear to tread. Our goal was to build NOHZ_FULL and test the hell out of it. Nowadays we take this feature for granted in both the financial industry as well as telco where without nohz_full (I am told), all the worlds packets will be a few microseconds late. And that is not good.
You can see some of my nohz_full work here (or read the RHEL docs on the subject, as I wrote those too).
While Red Hat was not my first job, I do consider Red Hat my first (job) love. It is the first job I had that I’d call career-worthy, in that I could see myself working here for a while (there was plenty of work and the company was growing).
I tried hard to make it work. But I could never get the results I wanted. The crisp video, clean audio, the BOKEH. Herein lies my adventures (full send, some might say) over the past ~2 months in getting a proper home office A/V setup. It’s not perfect yet, but I’m fairly happy with the improvement. I’ll close this write-up with some of my next steps / gaps.
Starting with some basic tenets:
Whatever I end up with has to augment all of my ingrained behaviors; I’m not going to relearn how to use a computer (change operating system) for the sake of this.
I’m stuck with the room I’ve got. The walls have odd angles which makes lighting difficult.
I don’t know anything about this, so there will be lots of trial, error, and Googling.
I started by scouring YouTube for videos about the ultimate camera setup for WFH. It turns out the center of knowledge in this area is Twitch streamers. There are also a few companies posting setups who are more business focused, feels like they’re using these videos to promote their consulting businesses (which are around video editing, or promoting small business). Twitch streamers also know a lot about Open Broadcaster Software, but I’ll get to that in a bit.
Camera
After seeing this blog come across my Twitter, I impulse-buy a GoPro Hero 8 Black. Turns out GoPro is completely ignoring Linux and their webcam firmware is really, really beta even on Mac and Windows. Returned it.
After watching a lot more of these videos, I started seeing a trend towards a particular Mirrorless DSLR camera, the Canon EOS M50. I’m trying to stay with models that folks recommend for WFH/streaming, and that I can find SOMETHING saying they support Linux / have anecdotal evidence of it working. So I bought a Canon M50. I had to buy it from a place I hadn’t shopped at before (Best Buy), because a lot of people are trying to up their WFH A/V game, making components scarce.
So I’ve got the camera. I also need a micro HDMI –> USB 3 cable, so I got one of those. Elsewhere in the YouTube blackhole, I came across the term “dummy battery”. This is a hollow battery that lets you plug the camera directly into wall power to avoid having to use real batteries and their runtime limitations. Canon dummy batteries were sold out everywhere, including Canon themselves, although I did place an order with them directly (their web purchasing experience is stuck in early 2000s). It was on backorder, so I eventually canceled that order and bought a knockoff dummy battery for 20% of the price of the real one. Was I worried that something 20% cheaper would instantly fry my camera? Yep. But I am in full send mode now.
So I have the camera, the HDMI cable, the dummy battery. I probably need a tripod, right? I think cameras need tripods. OK, I got a tripod. Not sure what I’ll use it for, but I can always return it. Turns out the tripod was a key investment in making sure the camera is stable, level and oriented properly for the right angle.
Next I probably need a memory card, right? Cameras need memory cards? OK, I’ll get a memory card. But which one? I’m planning to put down 4k video @ 60 fps so “sorting by least expensive” is probably not the right move. Turns out there is a whole disaster of categorization of memory card performance. I ended up reading, and re-reading this page a few times. What a nightmare. The least consumer-friendly thing since 802.11 spec naming. Anyway I ended up buying a 128GB class 10 card and it seems to be fine.
I then have to connect the camera to my computer. The videos suggest HDMI, but Canon has recently announced USB support for live-streaming. This blog in particular was referenced in a few videos. Lets try that. OK, now I am into the land of having to configure and load out of tree kernel modules. How do you do this again? It’s been a while. OK, got it. Whew. How badly do I want the BOKEH? This is getting dicey and doesn’t feel right.
Well, it actually works. But it is FAR from ideal. The fact that I’ve got to run gphoto2 on boot, and install all this goop to wire things together … there has to be a better way?
I began using this setup for the first time in real video calls (we use Google Meet where I work). The quality was infinitely improved (making sure my Meet config used 720p and after literally days of experimentation with camera settings). People immediately noticed the difference too. However, sometimes the camera would shut off? I noticed a trend of it shutting off after about a half hour? But I have the dummy battery. What’s going on?
I will spare you the suspense. If I’d found this page, I’d never have bought the Canon M50. It shuts off after a half hour on purpose. There’s no way around it. Also the Canon M50 is not compatible with Magic Lantern firmware. What is Magic Lantern? Something I don’t want to deal with. Gone are my days of CyanogenMod on my Palm Pre (by the way, the Palm Pre was better than any phone I’ve owned before or since, don’t @ me).
So, my Canon shuts off. That’s just about the worst flaw it could have. Back to Best Buy. But not before the 14 day return policy expires, so I can’t do it online, I now have to physically visit a Best Buy to haggle, or eBay it. Despite COVID situation, I decided to mask it and haggle. Luckily they took the camera back, yay. If you’re interested in why it turns off, I found this post which is probably right…yeesh!
Next, what camera should I go for? Elgato’s page made it super easy to find cameras of a similar price-point that didn’t have any glaring flaws.
After much more fact-checking, I decided to get a Sony A6100. This time Amazon had it in stock, and significantly cheaper than other sites (price gouging?). The Sony arrives and it is immediately more useful (because it doesn’t shut off). Incidentally, I had to buy a different dummy battery for the Sony. An off-brand, that has thus far not fried my camera. Tripod, memory card and HDMI cable were compatible.
Next, how to connect this to my computer. The Sony also supports USB, but I’m not happy with the quality. It also uses a lot of CPU. What solutions are there? After many a sleepless night on YouTube learning what a “capture card” is, I went to find the highest end model, and found an Elgato 4K60 PRO PCI capture card. Wow, this was a total waste of time. Not only does it have zero Linux support but it feels like Elgato is actively ignoring Linux across the board, which is possibly corroborated by my experience with their CamLink 4K as well(?). I end up searching my email for that phrase in case some other intrepid Red Hatter is further along than me.
It turns out that an engineer whom I hired ~4 years ago, and who I allegedly sit next to in the office (it’s been 6+ months, and I’m full sending my home office, maybe I’ll never see him again), wrote a post about capture cards in May 2020! I have learned to trust this person’s opinion on these sorts of niche devices, because he has described his enviable Plex setup (it has a dedicated air conditioner), his GPU bitcoin mining, Threadripper prowess, and other things to me over lunch which indicate he has a nack for understanding things at the level of detail that I need for my BOKEH. His post pointed to a Magewell USB Capture HDMI 4K Plus Device. In particular he had tested it on Fedora and noted how hands-off it was for setup. His complaint was noise about a built-in fan. After balking at the price, I decide that it can be returned, so I get one. It turns out he was right, and it works great! One thing though is that I haven’t heard the fan at all, which I guess is good. Thanks to Sebastian for this tip.
However its really expensive. And the YouTubers are telling me about Elgato CamLink 4k which is 1/3rd the price. I get a CamLink 4K and decide that if it works, I’ll return the Magewell to save the money. Hook up the CamLink, the kernel sees it as a uvc device, but I see nothing but a black screen in OBS and Google Meet. After an hours worth of effort and Google turning up several complaints on this topic (admittedly not a huge effort on my part), I decide to trade money for my weekends/evenings back, and stick with the Magewell. Sebastian was right again. Hat-tip.
Audio
On to Audio. Last year I hired an engineer who turned out to be in two metal bands. On video calls with him, he had what looked like a very serious A/V setup in his home office. If you’re into Dual-Violin US Folk Metal, maybe check them out. Anyway, this person gave me some guidance on audio and I ended up going with a Blue Yeti USB Mic. This is one aspect of this journey that worked on the first try. However I could not help but think maybe there’s a way to improve? At conferences, when they were in-person, presenters get a lavalier mic. I bought one and it wasn’t any better. Also it was annoying to have a cable dangling from my collar all day. Returned.
For years I’ve been using Bose active noise cancelling headphones (at the office which is an open-office disaster / cacophony). At home I also bought Bose ones, but the in-ear model. The only thing I don’t like is that they’re wired, so I’m tied to the desk. One thing I do like is that they’re wired, so I never have to worry about batteries like I do with the ones I have at the office. I also have a pair of noise cancelling Galaxy Buds (which I love). I decide to try those. Ahh, my workstation doesn’t have Bluetooth. Back to Amazon to get a cheap bluetooth dongle. And now the Galaxy Buds work. But the experience sucks, for a few reasons:
I have to worry about batteries
They disconnect if I walk down the hall
Pairing is less than ideal in Linux where I have ~5 audio devices
I notice a lot of CPU usage tied back to the Bluetooth device…not good.
I have the Video and Audio basically squared away at this point. What’s next? Lighting.
Lighting
The majority if howto videos indicate that if you don’t have proper lightning, it won’t matter your camera or software. I begin to research lighting, and found that Elgato Key Lights are a popular thing. You apparantly need two of them, they’re $200 each, and they’re out of stock. So, nope. I have a spare floor lamp and decide to use that. This is much better than the ceiling fan light I had which was casting a very scary shadow on my face 🙂 So the lamp is to my east-south-east, pointed towards the ceiling and I’m OK with the results. This is an area I may eventually want to improve, but maybe I’m nearing diminishing returns time-wise?
Software
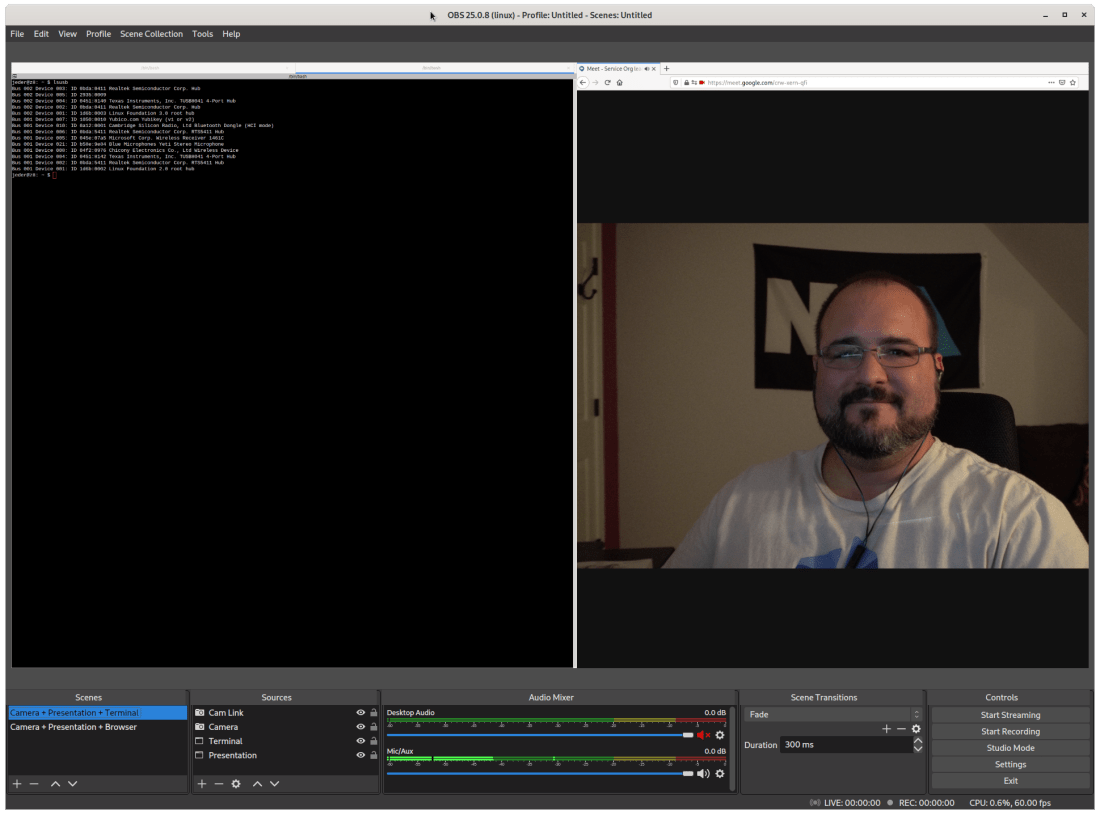
Conferences have gone virtual, and I have several presentations lined up, which are all typically recorded. So now I need to figure out how to record myself. According to YouTubers, I need to figure out what OBS stands for. The Open Broadcaster Software is (apparently) an open source streaming/recording application available for Windows, Mac and Linux. I am now watching EposVox masterclass on OBS. It’s complicated but not terrible to do basic stuff. You can see my first stab at integrating my efforts into a recorded presentation here.
After watching that video back, I have a few areas to improve:
I keep having to pause the recording to load the next section of content into my brain. I have to keep looking down to pause. There are apparently things called Elgato Stream Decks, which are a pad of hotkeys which are used by game streamers to automate certain operating system or OBS operations. OBS also supports hotkeys. Here is what my OBS canvas looks like including a few video sources and scenes:
I am not looking into the camera often enough. Yes, I have to look at my monitor to do demos and whatnot (expected), but I am also looking at my monitor to check my notes. I want to avoid that somehow. It turns out that Phone-based Teleprompters are a thing, and in-expensive. I bought one. It’s freaking cool. Mounts directly to the camera lens and displays the “script” overlaying the lens itself. So you are staring directly at the lens, and have a “Star Wars intro” style scrolling text of your content. Cannot recommend this product enough for professional delivery of recorded content. It even comes with a Bluetooth remote to control scrolling speed and start/stop. That dongle comes in handy again!
I want to involve whiteboards in my presentations. In the office, I have whiteboards available to me everywhere. I need one at home. But due to the size and shape of my office, I really don’t have a wall within camera-range to mount one. So I went with one on wheels. I haven’t used it in any presentations yet, but I’ve been using it for keeping notes and so far loving it.
I have to learn how to do basic video editing. After some Googling for the state of the art on Linux, I found Kdenlive which isn’t terrible to learn, after watching a few beginners videos.
I realize the audio is out of sync with the video. OBS let me insert a delay to help match then up. 300ms seems to be perfect.
In the original version of this video, the audio was super low. So I had to learn how to convert an mkv (OBS default) to an mp4, so I can work with the audio independently of the video, and boost the audio gain (by +20dB if you’re curious). Thanks to some quick tips from Langdon White I am able to achieve this. At this point my various experiments and YouTube deep dives are starting to pay off. I am smiling, finally 🙂
Next Steps
For some reason, when I turn off the camera, the zoom level resets to 16mm. But I want it at 18mm. So every time I turn the camera power on, I have to dial the zoom back in manually. Not a huge deal since it’s just once a day.
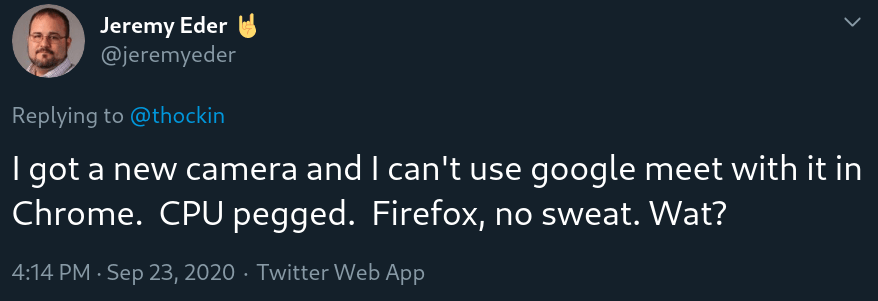
CPU usage in Chrome…brings the computer to a crawl. My workstation has 16 cores and 64G RAM. Sigh…so now all my Google Meets occur in Firefox. Not too bad, just annoying when it comes to screensharing since I really do not want to use Firefox as my primary browser.
Lens: according to photography snobs, if I don’t get a better lens, they’ll throw me out of the subreddit. This will probably have to wait until after my winning lotto ticket shows up.
After talking with some coworkers who are also upleveling their WFH A/V setups and thus learning what OBS stands for, I come to find out that OBS has some noise filtering options built in. I could have used that to filter out some background noise (e.g. from my kids or my workstation fans).
Conclusion / Final Hardware list
So, in the end, my hardware and software setup as of this posting is:
I have to say, this has been a really fun project. It’s an area I had zero knowledge of going in – just a personal goal to improve my WFH A/V. It’s also an area of somewhat daunting complexity, hardware opinions (nerd fights), and an endless compatibility matrix. That’s part of why I went the route of buying stuff and returning it [1].
I hope this post helps someone who is looking to improve their home office video quality avoid newb mistakes and just get it done. Also, I do realize that there are likely cheaper options across the board. But at least you have the laundry list of stuff that worked for me, within my given constraints, and can possibly phase your purchases like I did over a couple months.
I came really close to making some large purchases to improve my video call situation, and I may still do so, but I did spend some time and found a few quick wins maybe will help others:
I use Fedora as my workstation. Won’t change it.
I have a Logitech C930e. Logitech doesn’t publish anything on how to tweak the camera on Linux. Figure out how to tweak it.
I like (love) working in the dark. So I never have any lights on. That has to change.
I have a window behind me in my home office. Shutting the blinds is not enough. Repositioning my desk won’t work in the space I’ve got. Get a blackout curtain.
My webcam is sitting on top of my monitor, dead center. This makes it really awkward to look directly at. It’s about 8″ above my eye-line. I don’t think I’m going to change this. My eyeline has to remain at the center of the monitor or I get neck pain.
Here are the tweaks I made that do seem to have improved things:
dnf install v4l2ucp v4l-utils
v4l2-ctl --set-ctrl zoom_absolute=125 # this helps with the "know your frame" part https://www.youtube.com/watch?v=g2wH36xzs_M. This camera has a really wide FoV, so this shrinks it down a bit.
v4l2-ctl --set-ctrl tilt_absolute=-36000 # this helps tilt the center of the camera frame down towards where I'm sitting (8" below camera).
v4l2-ctl --set-ctrl sharpness=150 # This seemed to help the most. I tried a bunch of values and 150 is best for my office.
Lighting: Instead of having my desk lamp illuminate my keyboard, turn it 180degrees to bounce off the white ceiling. Big improvement.
Lighting: You can’t work in the dark anymore.
Auto-focus: I have a TV just to my right. When whatever’s on changes brightness, it makes the camera autofocus freak out. I typically keep the TV muted. Now I’ll pause it while on calls.
Microphone: I have an external USB mic (Blue Yeti). Turns out I had it in the wrong position relative to how I’m sitting. Thanks to a co-workers “webcam basics” slides for that tip (confirmed in Blue Yeti docs).
Despite that, after recording a video meeting of just myself I still didn’t like how the audio turned out. So I bought an inexpensive lavalier microphone from Amazon, figured it’s worth a try.
One thing I cannot figure out how to do is bokeh. I think that remains a gap between what I’ve got now and higher end gear.
Increased Capacity Planning and demand forecasting for production services
Widen availability to additional regions and cloud providers (have you built and supported production services on GCP?)
We’ve got several openings. They’re all REMOTE-FRIENDLY! Don’t worry about the specific titles – they’re a biproduct of how RH backend systems work.
If you think you check the majority of boxes on the job posting, and ESPECIALLY if you’ve done any of these things in the past…please ping us. We’re actively hiring into all of these roles ASAP.
So come have some fun with us. Build and run cool shit. Be at the forefront of operationalizing OpenShift 4. Develop in go. Release continuously.







 Wanted to share some updates info about the Service Delivery, SRE team at Red Hat for 2020!
Wanted to share some updates info about the Service Delivery, SRE team at Red Hat for 2020!