The use-case for per-application resource counters
Administrators of *NIX-based systems are quite accustomed to viewing resource counters strewn throughout the system, in places like /proc, /sys and more recently /cgroup or /sys/fs/cgroup. With the release of RHEL6 came widespread enterprise adoption of Control Groups (cgroups), which had been implemented steadily over a series of years, and vetted both there as well as in Fedora (RHEL’s upstream).
Implementing cgroups not only let sysadmins carve up a single OS into multiple logical partitions, it also bought them per-cgroup counters that the kernel maintains. That’s in addition to common use-cases such as quality of service guarantees or charge-back.
Docker’s unique twist
With the recent uptick in adoption of Linux containers (Docker encapsulates several mature technologies into an impressive usability package), administrators might be wondering where the per-container resource counters are. We’re in luck! Since Docker heavily relies on Cgroups, many of the counters that sysadmins are familiar with “just work”. They could benefit from some usability improvements, but if you’re comfortable spelunking through the cgroup VFS, you can dig them out fairly easily.
I should note that the specific hierarchy and commands below are specific to RHEL and Fedora, so you might have to customize some paths or package names for your system.
In the most recent versions of Fedora, engineers have begun building and shipping a binary called ‘nsinit‘, which is part of libcontainer, which is the “execution driver” for Docker. nsinit is a very powerful debugging utility that lets sysadmins not only view per-container resource counters, but also view the container’s runtime configuration and “jump into” a running container.
How to use the nsinit utility
First you should grab a copy from Fedora, or build it yourself. Building it yourself is an unnecessarily complicated exercise; so I’m glad they started building it for Fedora so you can just do:
# yum install --enablerepo=updates-testing golang-github-docker-libcontainer
$ rpm -qf `which nsinit`
golang-github-docker-libcontainer-1.1.0-7.git29363e2.fc20.x86_64
# nsinit
NAME:
nsinit - A new cli application
USAGE:
nsinit [global options] command [command options] [arguments...]
VERSION:
0.1
COMMANDS:
exec execute a new command inside a container
init runs the init process inside the namespace
stats display statistics for the container
config display the container configuration
nsenter init process for entering an existing namespace
pause pause the container's processes
unpause unpause the container's processes
help, h Shows a list of commands or help for one command
I’ll cover the most useful of nsinit’s capabilities; config, stats and exec.
Note: nsinit currently requires that you run it while you're inside the container's state directory. So from here on, all commands assume you're in there.
So, something like this:
# docker ps -q
4caad549289
# CID=`docker ps -q`
# cd /var/lib/docker/execdriver/native/$CID*
# ll
total 8
-rw-r-xr-x. 1 root root 3826 Sep 1 20:11 container.json
-rw-r--r--. 1 root root 114 Sep 1 20:11 state.json
Those files are plain-text readable, although not very human-readable. nsinit pretty-prints these files. For example, an abridged verison of the output of nsinit config (full version here). Note that you can get much of this info (but not all) from docker inspect.
# nsinit config
{
"mount_config": {
"mounts": [
{
"type": "bind",
"source": "/var/lib/docker/init/dockerinit-1.1.1",
"destination": "/.dockerinit",
"private": true
},
{
"type": "bind",
"source": "/etc/resolv.conf",
"destination": "/etc/resolv.conf",
"private": true
},
<snip>
"mount_label": "system_u:object_r:svirt_sandbox_file_t:s0:c631,c744"
},
"hostname": "4caad5492898",
"environment": [
"HOME=/",
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/goroot/bin:/gopath/bin",
"HOSTNAME=4caad5492898",
"DEBIAN_FRONTEND=noninteractive",
"GOROOT=/goroot",
"GOPATH=/gopath"
],
"namespaces": {
"NEWIPC": true,
"NEWNET": true,
"NEWNS": true,
"NEWPID": true,
"NEWUTS": true
},
"capabilities": [
"CHOWN",
"DAC_OVERRIDE",
"FOWNER",
"MKNOD",
"NET_RAW",
"SETGID",
"SETUID",
"SETFCAP",
"SETPCAP",
"NET_BIND_SERVICE",
"SYS_CHROOT",
"KILL"
],
"networks": [
{
"type": "loopback",
"address": "127.0.0.1/0",
"gateway": "localhost",
"mtu": 1500
},
{
"type": "veth",
"bridge": "docker0",
"veth_prefix": "veth",
"address": "172.17.0.6/16",
"gateway": "172.17.42.1",
"mtu": 1500
}
],
"cgroups": {
"name": "4caad5492898f1a4230353de15e2acfc05809c69d05ec7289c6a14ef6d57b195",
"parent": "docker",
"allowed_devices": [
<snip>
"process_label": "system_u:system_r:svirt_lxc_net_t:s0:c631,c744",
"restrict_sys": true
}
The stats mode is far more interesting. nsinit reads cgroup counters for CPU and memory usage. The network statistics come from /sys/class/net/<EthInterface>/statistics. From here you can see how much memory your application is using, chart it’s growth, watch CPU utilization, cross-check data from other tools, etc.
{
"network_stats": {
"rx_bytes": 180568,
"rx_packets": 89,
"tx_bytes": 28316,
"tx_packets": 92
},
"cgroup_stats": {
"cpu_stats": {
"cpu_usage": {
"total_usage": 985559718,
"percpu_usage": [
43613750,
79789656,
132486590,
78759739,
49063680,
60703059,
36277458,
35919550,
36329424,
20096103,
8148695,
25279255,
0,
0,
0,
6144761,
14814784,
2612915,
95162480,
33853872,
114861235,
71115914,
6533416,
33993382
],
"usage_in_kernelmode": 510000000,
"usage_in_usermode": 440000000
},
"throlling_data": {}
},
"memory_stats": {
"usage": 27992064,
"max_usage": 29020160,
"stats": {
"active_anon": 4411392,
"active_file": 3149824,
"cache": 22278144,
"hierarchical_memory_limit": 9223372036854775807,
"hierarchical_memsw_limit": 9223372036854775807,
"inactive_anon": 0,
"inactive_file": 19128320,
"mapped_file": 3723264,
"pgfault": 94783,
"pgmajfault": 25,
"pgpgin": 19919,
"pgpgout": 13902,
"rss": 4460544,
"rss_huge": 2097152,
"swap": 0,
"total_active_anon": 4411392,
"total_active_file": 3149824,
"total_cache": 22278144,
"total_inactive_anon": 0,
"total_inactive_file": 19128320,
"total_mapped_file": 3723264,
"total_pgfault": 94783,
"total_pgmajfault": 25,
"total_pgpgin": 19919,
"total_pgpgout": 13902,
"total_rss": 4460544,
"total_rss_huge": 2097152,
"total_swap": 0,
"total_unevictable": 0,
"unevictable": 0
},
"failcnt": 0
},
"blkio_stats": {}
}
}
nsenter is commonly used to run a command inside an existing container, something like
# nsenter -m -u -n -i -p -t 19119 bash
Where 19119 is the PID of a process in the container. Ugly. nsinit makes this slightly easier (at least IMHO):
# nsinit exec cat /etc/hostname
4caad549289
# nsinit exec bash
bash-4.2# exit
nsinit’s capabilities and reported statistics are incredibly useful when debugging the implementation of QoS for each container, implementing/verifying resource-ceilings/guarantees, and for a more complete understanding of what your containers are doing.
This area is fast-moving…I did want to call out two other important developments, which should ultimately have more broad applicability than nsinit.
Google has published a project called cAdvisor that provides a basic web interface, but more importantly an API for higher layers (such as Kubernetes) to use.
Red Hat has proposed container support for Performance Co-Pilot, a system-level performance monitoring utility in RHEL7, along with goals of teaching many other tools about containers.


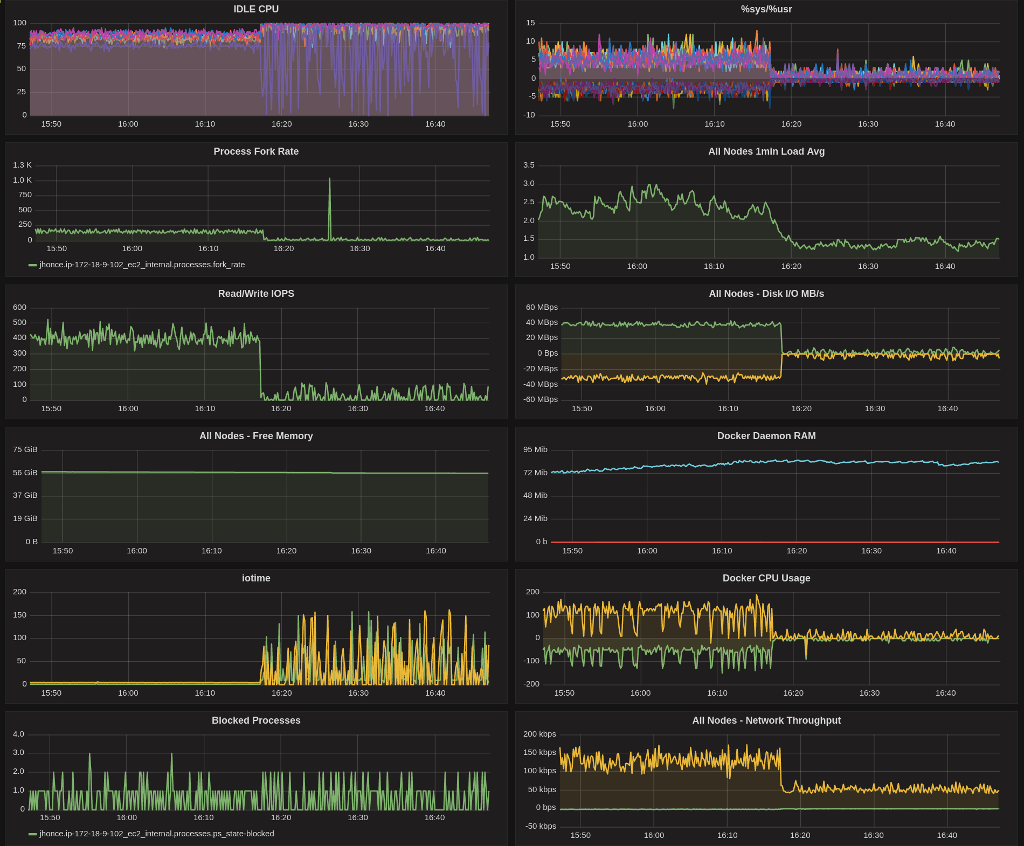




 storage device used for docker’s graph storage.
storage device used for docker’s graph storage.



{kind=link}